背景 在日常开发中,我们经常会遇到树形结构的数据查询。以用户地址为例,在填写用户地址的时候,我们一般需要定位到用户所属的省、市、区等信息,这里的省、市、区就是典型的树形结构。
当我们在搜索栏输入搜索信息时,搜索栏会调用后端接口,来展示对应的参考搜索信息列表。在输入地址信息时,我们也遇到了类似的需求,通过输入的信息,获取与之相匹配的区划名称。要完成这个需求,有几种实现方式:
数据库模糊搜索:将搜索内容作为数据库查询条件,通过like关键字与区划名称进行模糊搜索。
搜索引擎:引入搜索引擎,如elasticSearch,预先将区划名称导入到搜索引擎中,将搜索内容作为查询条件,调用搜索引擎进行查询。
通过Tire数据结构进行前缀匹配:将输入内容作为查询条件,在Tire树中,进行匹配,获取符合匹配的数据。
因为用户输入搜索内容时,会实时发送对应的请求到后端,获取相关的匹配列表,如果使用数据库模糊搜索的话,一方面模糊查询数据较慢,另一方面,请求数较多,数据库较难承受,因此这个方案不可行。
通过搜索引擎进行搜索,能获取到与之匹配或相关的区划信息,但同时也会增加开发的成本,为一个比较简单的需求引入一个复杂的中间件不值得。
通过综合考虑会,这里决定使用Trie数据结构,来将搜索条件进行前缀匹配,以获取匹配的数据。
TrieTree实现区划查询 TrieTree定义 Tire是一种数状数据结构,可以紧凑地存储字符串,它的主要思想包括以下内容:
trie是一种树状的数据结构
根代表一个空字符串
每个节点存储一个字符并有多个子节点,每个节点对应一个可能的字符
每个树节点代表一个单词或一个前缀字符串
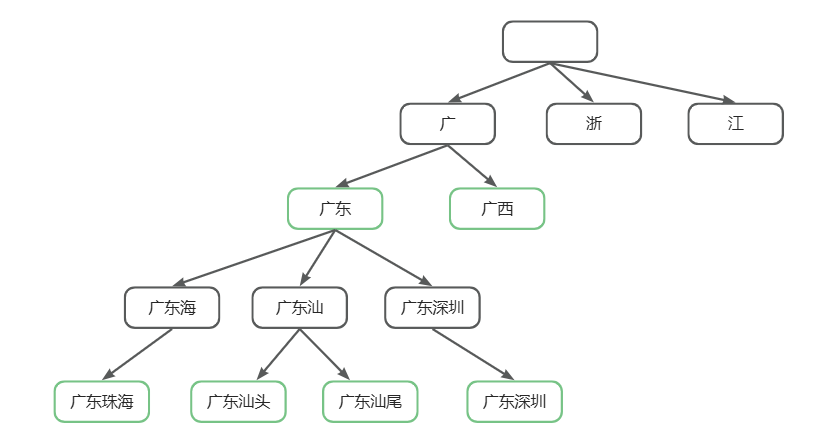
TrieTree前缀树类定义 如上图所示,对于区域划分,我们将区划全称依次加入到TrieTree后,生成的TrieTree的部分结构上图所示。在这棵TrieTree树中,叶子节点都是在我们数据库中真实存在的区划名称,而中间节点,有一些只是起到链接作用,而有一些也是数据库中真实存在的区划名称,比如广东、广西。针对上述的结构,我们定义的TrieNode结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.yang.core.infrastructure.trie;import lombok.Data;import java.util.HashMap;import java.util.Map;@Data public class TrieNode {private Character ch;private String currentValue;private boolean isLeaf;private boolean isWord;private int level;public TrieNode () {this .level = 0 ;this .isLeaf = false ;this .isWord = false ;public TrieNode (int level) {this .level = level;this .isLeaf = false ;this .isWord = false ;private Map<Character, TrieNode> childNodeMap = new HashMap <>();public void put (Character ch, TrieNode child) {public TrieNode get (Character ch) {return childNodeMap.get(ch);
TrieNode只是我们前缀树的节点,我们还需要定义前缀树类,用于操作这些TrieNode节点,包括新增、匹配查询等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 package com.yang.core.infrastructure.trie;import lombok.Data;import java.io.Serializable;import java.util.ArrayList;import java.util.LinkedList;import java.util.List;import java.util.Queue;@Data public class TrieTree implements Serializable {private TrieNode root = new TrieNode ();public void add (String word) {0 );public void add (TrieNode t, char [] chars, int start) {if (start == chars.length) {true );return ;for (int i = start; i < chars.length; i++) {char ch = chars[i];TrieNode child = t.get(ch);if (child != null ) {1 );break ;new TrieNode (t.getLevel() + 1 );null ? t.getCurrentValue() + ch : "" + ch);if (i == chars.length - 1 ) {true );true );private TrieNode rootOfMatchWord (String word) {return rootOfMatchWord(this .root, word.toCharArray(), 0 );private TrieNode rootOfMatchWord (TrieNode root, char [] chars, int start) {if (start == chars.length) {return root;char ch = chars[start];TrieNode child = root.get(ch);if (child == null ) {return null ;return rootOfMatchWord(child, chars, start + 1 );public List<TrieNode> matchWord (String word) {TrieNode t = rootOfMatchWord(word);if (t == null ) {return new ArrayList <>();new ArrayList <>();new LinkedList <>();while (!queue.isEmpty()) {TrieNode head = queue.poll();if (head.isWord()) {for (TrieNode child : head.getChildNodeMap().values()) {return matchWordTrieNodeList;@Override public String toString () {new LinkedList <>();StringBuilder result = new StringBuilder ();while (!queue.isEmpty()) {StringBuilder stringBuilder = new StringBuilder ();int size = queue.size();for (int i = 0 ; i < size; i++) {TrieNode t = queue.poll();"(" ).append(t.isWord()).append(") " );for (TrieNode child : t.getChildNodeMap().values()) {"\n" );return result.toString();
我们执行下列代码,用来测试TrieTree的添加、查询方法是否正确:
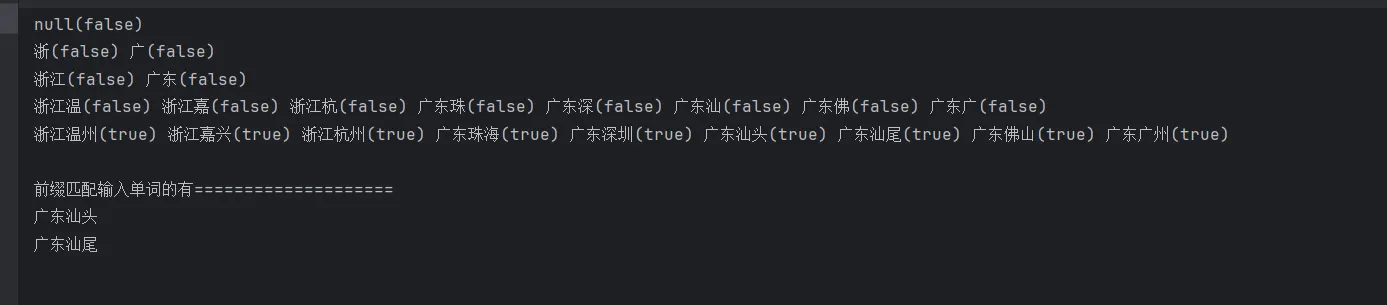
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test "广东汕头" );"广东汕尾" );"广东广州" );"广东深圳" );"广东珠海" );"广东佛山" );"浙江温州" );"浙江杭州" );"浙江嘉兴" );List <TrieNode> matchWordList = trieTree.matchWord("广东汕" );"前缀匹配输入单词的有====================" );for (TrieNode trieNode : matchWordList) {
执行结果如下:
区划前缀树构建 初步实现 在应用启动的时候,我们从数据库中查询出所有地址区划信息,并将其数据插入到我们的地址前缀树种,在查询的时候,通过地址前缀树,匹配到对应的地址信息,并返回给前端:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Component class RegionPrefixTrieNodeHelper { @Autowired List <String> matchRegionNameList(String word) {List <TrieNode> trieNodes = regionTrieTree.matchWord(word);if (CollectionUtils.isEmpty(trieNodes)) {return new ArrayList<>();return trieNodes.stream().map (TrieNode::getCurrentValue).collect(Collectors.toList()); @PostConstruct List <RegionModel> regionModelList = regionRepository.queryAll();for (RegionModel regionModel : regionModelList) {
domain层实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /**return List <String> queryRegionFullNameByTrieTree(String inputWord) {return regionPrefixTrieNodeHelper.matchRegionNameList(inputWord);return List <RegionModel> likeQueryRegionFullName(RegionLikeQueryDomainRequest request) {return regionRepository.likeQueryRegionModelList(regionLikeListQueryRequest);
facade层实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override List <String>> prefixMatchRegionNameByWord(String word) {List <String> regionFullNameList = regionDomainService.queryRegionFullNameByTrieTree(word);if (!CollectionUtils.isEmpty(regionFullNameList)) {return ResultT.success(regionFullNameList);List <RegionModel> regionModelList = regionDomainService.likeQueryRegionFullName(domainRequest);if (CollectionUtils.isEmpty(regionFullNameList)) {return ResultT.success();return ResultT.success(regionModelList.stream().map (RegionModel::getRegionFullName).collect(Collectors.toList()));
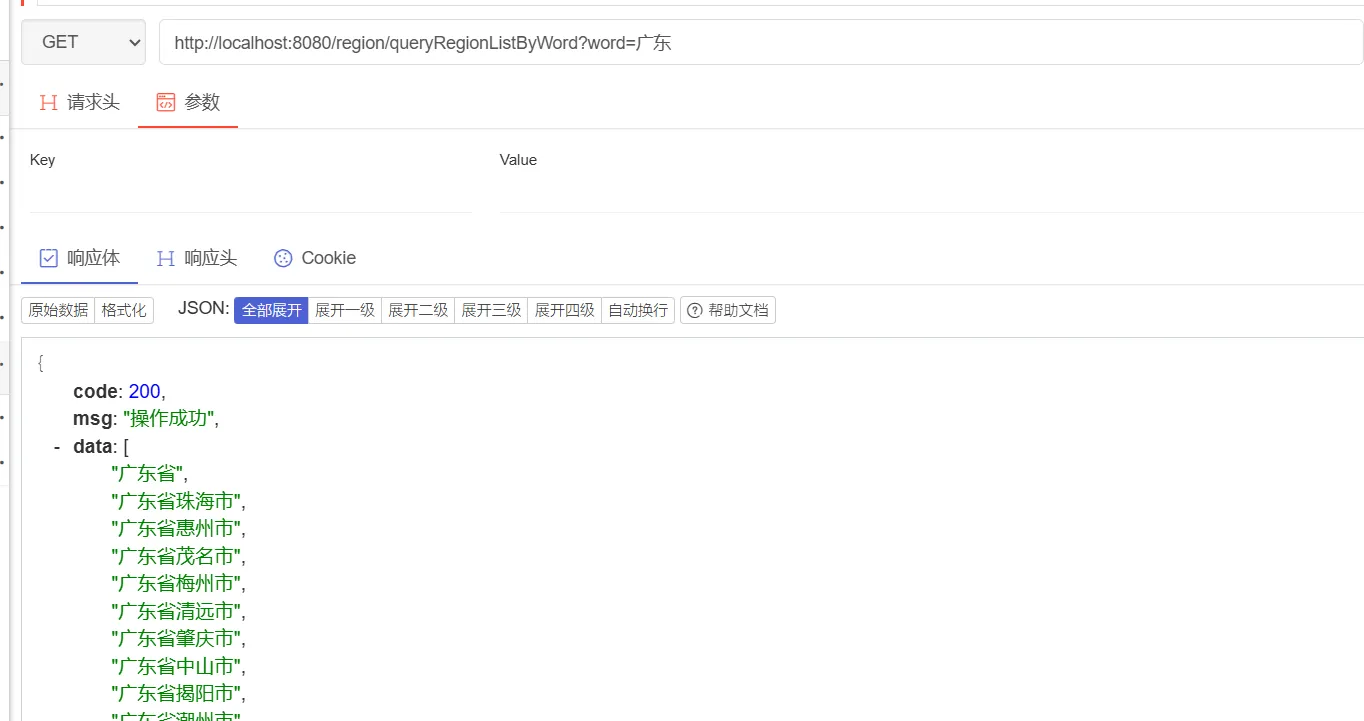
我们启动项目,访问相关的controller,查询结果如下:
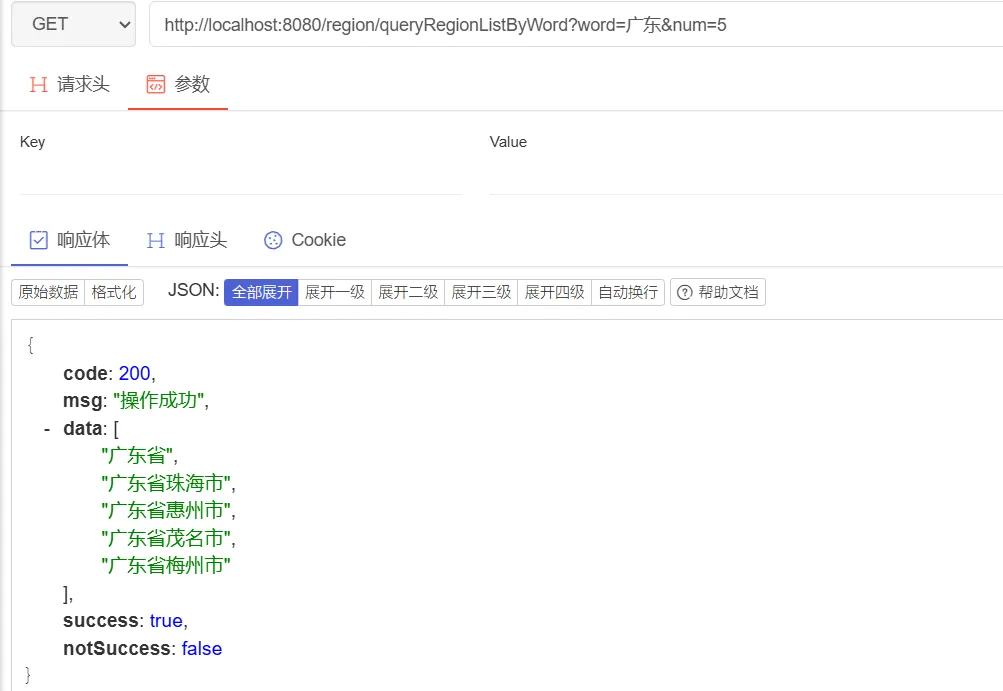
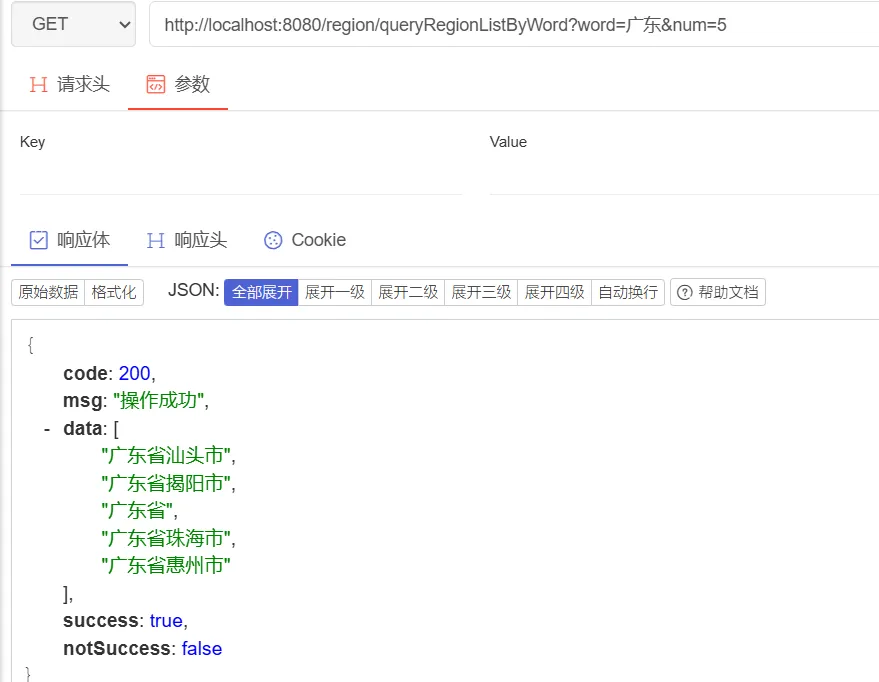
返回体大小优化 但上述的方式存在一个问题,当我们输入的内容较少,比如只输入“广”时,那么前缀树会将所有的以广开头的地址,都返回,这会导致返回的数据体报文很大,因此,我们需要限制返回的数据体大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 // Controller层@GetMapping(value = "/queryRegionListByWord" ) List <String>> queryRegionListByWord(@RequestParam(name = "word" , required = true) String word, @RequestParam(name = "num" , required = false ) Integer num) { if (num == null) {10 ;return regionReadFacade.prefixMatchRegionNameByWord(word, num); @Override List <String>> prefixMatchRegionNameByWord(String word, Integer num) {List <String> regionFullNameList = regionDomainService.queryRegionFullNameByTrieTree(word);int size = regionFullNameList.size();if (!CollectionUtils.isEmpty(regionFullNameList)) {return ResultT.success(regionFullNameList.subList(0 , size < num ? size : num));List <RegionModel> regionModelList = regionDomainService.likeQueryRegionFullName(domainRequest);if (CollectionUtils.isEmpty(regionFullNameList)) {return ResultT.success();return ResultT.success(regionModelList.stream()map (RegionModel::getRegionFullName)0 , size < num ? size : num));
我们重新启动项目,访问结果如下,此时只会匹配出符合要求的前五个地址区划信息。
按照热度排序 对于这些地址区划信息,其实会存在一个热度问题,有些区划是经常被访问的,但我们之前定义的前缀树结构,并没有体现出这些区划信息的热度,因此需要进行改造,首先,我们修改TrieNode节点,将currentValue这个属性类型修改为泛形。后续我们会将热度作为currentValue的一部分进行存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Data class TrieNode <T> {int level;0 ;int level) {return childNodeMap.get(ch);
然后修改TrieTree,将构建TrieNode当前值的行为,抽象为方法,由子类实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 @Data class TrieTree <T> implements Serializable {0 );int start) {if (start == chars.length) {return ;for (int i = start; i < chars.length; i++) {if (child != null) {1 );break ;1 );if (i == chars.length - 1 ) {return return rootOfMatchWord(this.root, word.toCharArray(), 0 );int start) {if (start == chars.length) {return root;if (child == null) {return null;return rootOfMatchWord(child, chars, start + 1 );return List <TrieNode<T>> matchWord(String word) {if (t == null) {return new ArrayList<>();List <TrieNode<T>> matchWordTrieNodeList = new ArrayList<>();while (!queue.isEmpty()) {if (head.isWord()) {for (TrieNode<T> child : head.getChildNodeMap().values()) {return matchWordTrieNodeList; @Override while (!queue.isEmpty()) {int size = queue.size();for (int i = 0 ; i < size; i++) {"(" ).append(t.isWord()).append(") " );for (TrieNode<T> child : t.getChildNodeMap().values()) {"\n" );return result.toString();
定义RegionTrieNodeValue,该类有两个属性:regionFullName——当前区划的全称,value——当前区划的热度值。
1 2 3 4 5 6 7 8 9 10 @Data class RegionTrieNodeValue implements Serializable {0 );
定义RegionTrieTree,继承自TrieTree,作为区划业务的前缀树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class RegionTrieTree extends TrieTree<RegionTrieNodeValue> { @Override if (rootCurrentValue == null) {"" + ch);return trieNodeValue;"" + ch : rootCurrentValue.getRegionFullName() + ch;return currentValue;
最后,修改RegionPrefixTrieNodeHelper,添加递增热度的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Component class RegionPrefixTrieNodeHelper { @Autowired List <String> matchRegionNameList(String word) {List <TrieNode<RegionTrieNodeValue>> trieNodes = regionTrieTree.matchWord(word);if (CollectionUtils.isEmpty(trieNodes)) {return new ArrayList<>();List <RegionTrieNodeValue> regionTrieNodeValueList = trieNodes.stream().map (TrieNode::getCurrentValue)sorted ((node1, node2) -> node2.getValue().get() - node1.getValue().get())return regionTrieNodeValueList.stream().map (RegionTrieNodeValue::getRegionFullName) @PostConstruct List <RegionModel> regionModelList = regionRepository.queryAll();for (RegionModel regionModel : regionModelList) {
然后我们还需要暴露一个增加热度的方法,当用户选择了某一个区划后,调用该方法来增加对应区划的热度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 // controller层@PostMapping(value = "/chooseRegion" ) "word" ) String word) {return regionReadFacade.chooseRegion(word); @Override try {"chooseRegion" )"regionFullName" , regionFullName)return ResultT.success(true);
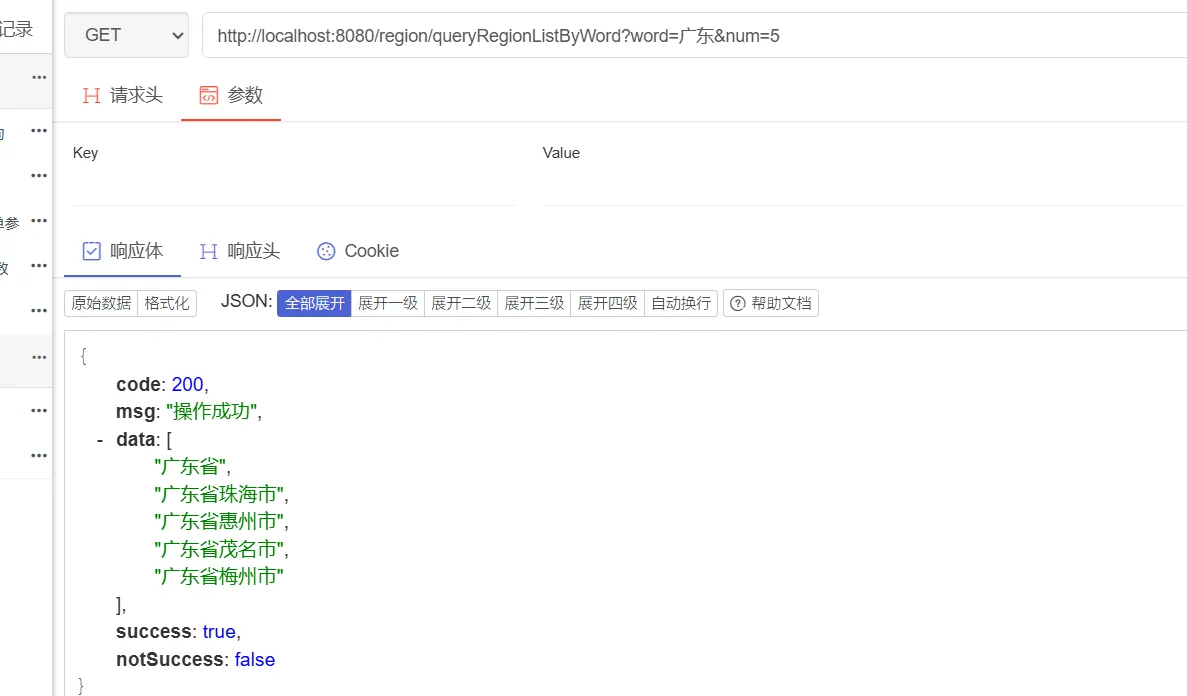
启动项目,首先查询区划列表,“广东”查询条件返回的前五个区划查询结果如下所示:
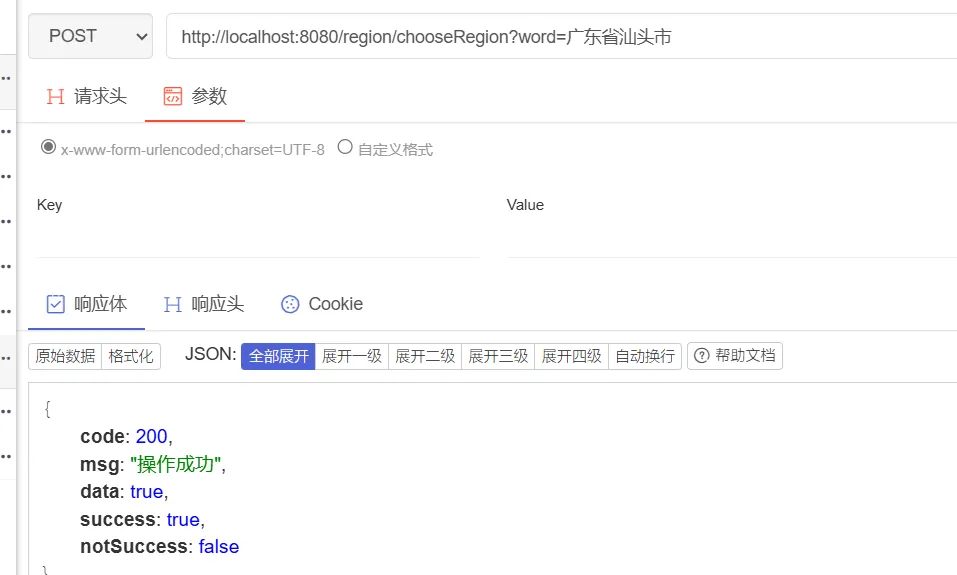
然后,我们访问chooseRegion方法,模拟用户选择某一个区划的行为:
再次查询”广东“,结果如下: